Beyond Gemini 2.0: Why ChatDOC PDF Parser is Your Better Choice
Splitting PDFs into clean, machine-readable text chunks remains a critical challenge for RAG systems. While open-source and specialized solutions exist, none truly balance accuracy, scalability, and cost-effectiveness. On January 5, 2025, Google released Gemini 2.0, marking a breakthrough in PDF processing (details:https://developers.googleblog.com/en/gemini-2-family-expands/)
Gemini 2.0 Flash: Key Improvements
Compared to existing tools, Gemini 2.0 Flash demonstrates notable advancements:
- Enhanced Accuracy: Excels at parsing most standard PDF types with precise information extraction.
- Unmatched Cost Efficiency: Priced at $1 per thousand pages, significantly undercutting market alternatives.

Limitations of Gemini 2.0 Flash
Our rigorous testing reveals critical shortcomings in this LLM-based approach:
1. Unable to Generate Accurate Bounding Box Information
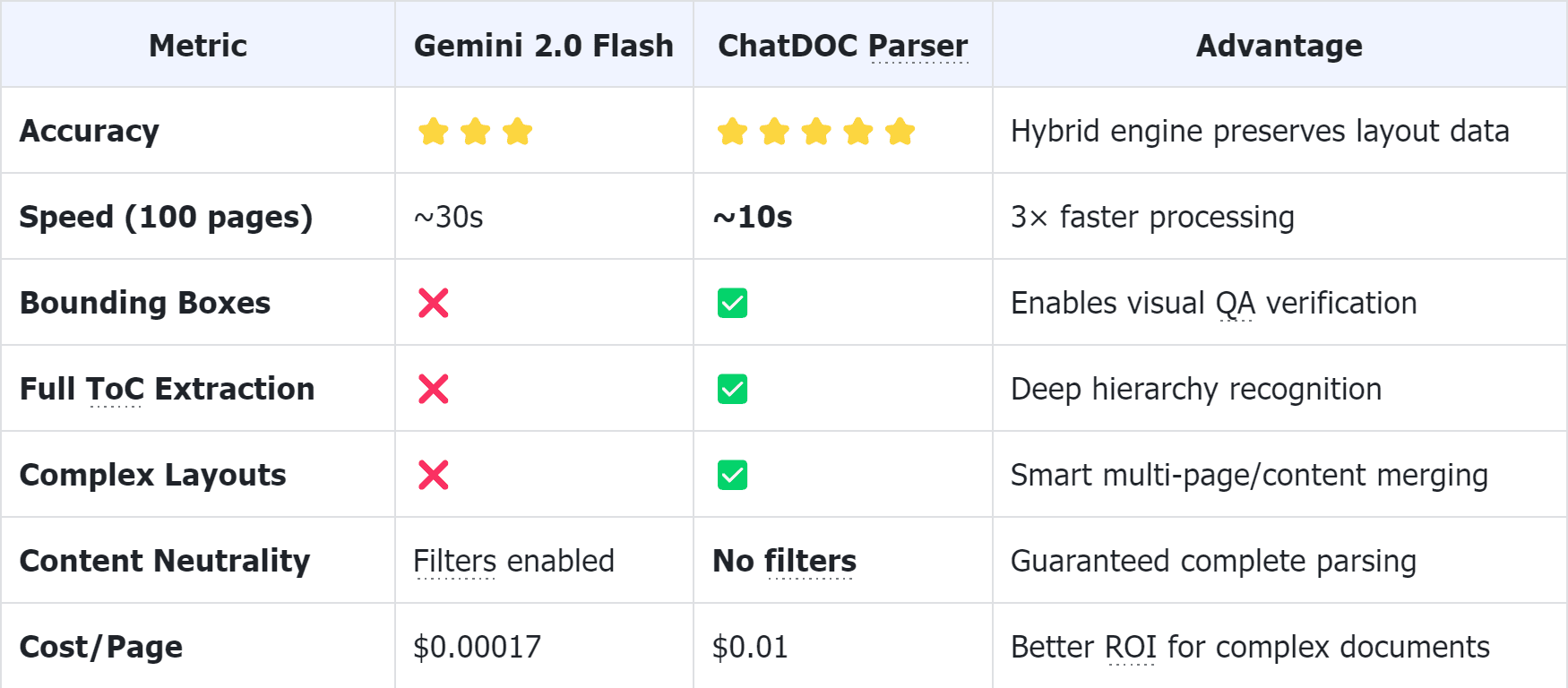
The article "Ingesting Millions of PDFs and why Gemini 2.0 Changes Everything" highly praises the performance of Gemini 2.0 Flash in PDF parsing but also highlights a significant shortcoming: Gemini 2.0 Flash cannot provide accurate text bounding box information.
In Retrieval-Augmented Generation (RAG) scenarios, effective PDF parsing and segmentation are essential for improving the accuracy of question answering. Accurate text bounding box information is critical for mapping extracted data back to its original context within the document. However, Gemini 2.0 Flash's inability to generate precise bounding box data forces users to rely only on page numbers or paragraph footnotes when tracing document content. This limitation prevents users from directly pinpointing specific information in the original document, making it challenging to efficiently verify the accuracy and reliability of the content generated by large language models in RAG workflows.
2. Struggles with Complex Layouts
Performance degrades with Multi-page tables、Multi-column paragraphs、Nested tables、Mathematical formulas、Cross-page content breaks.
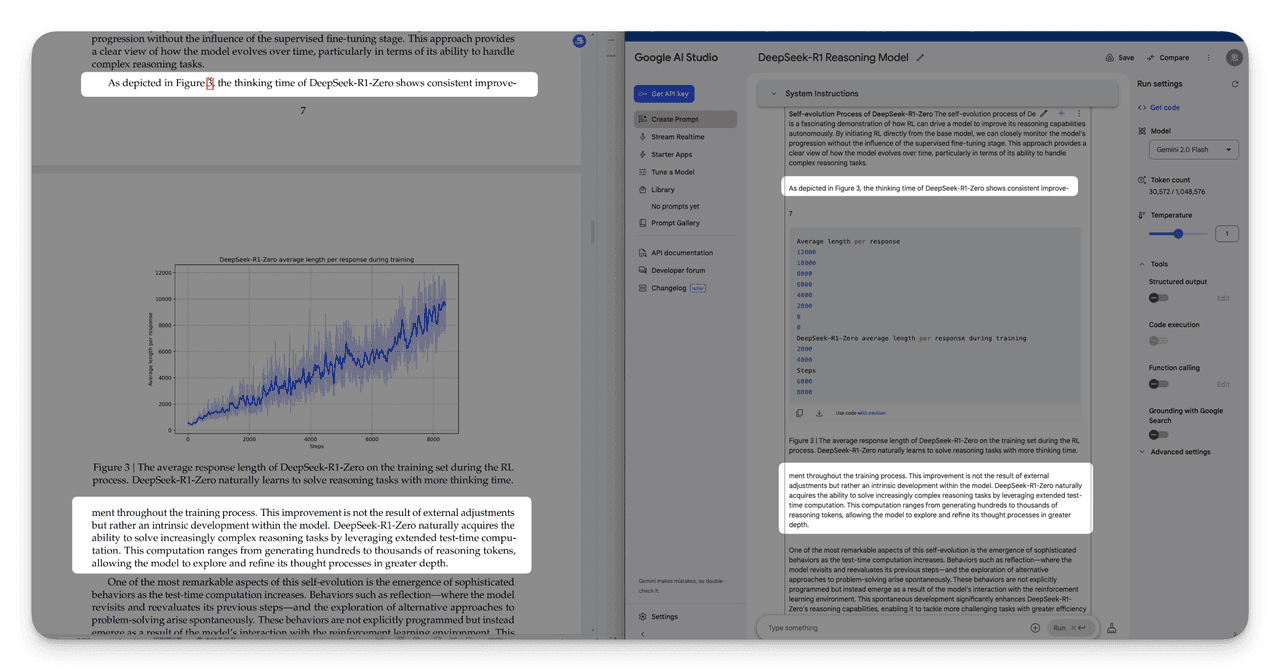
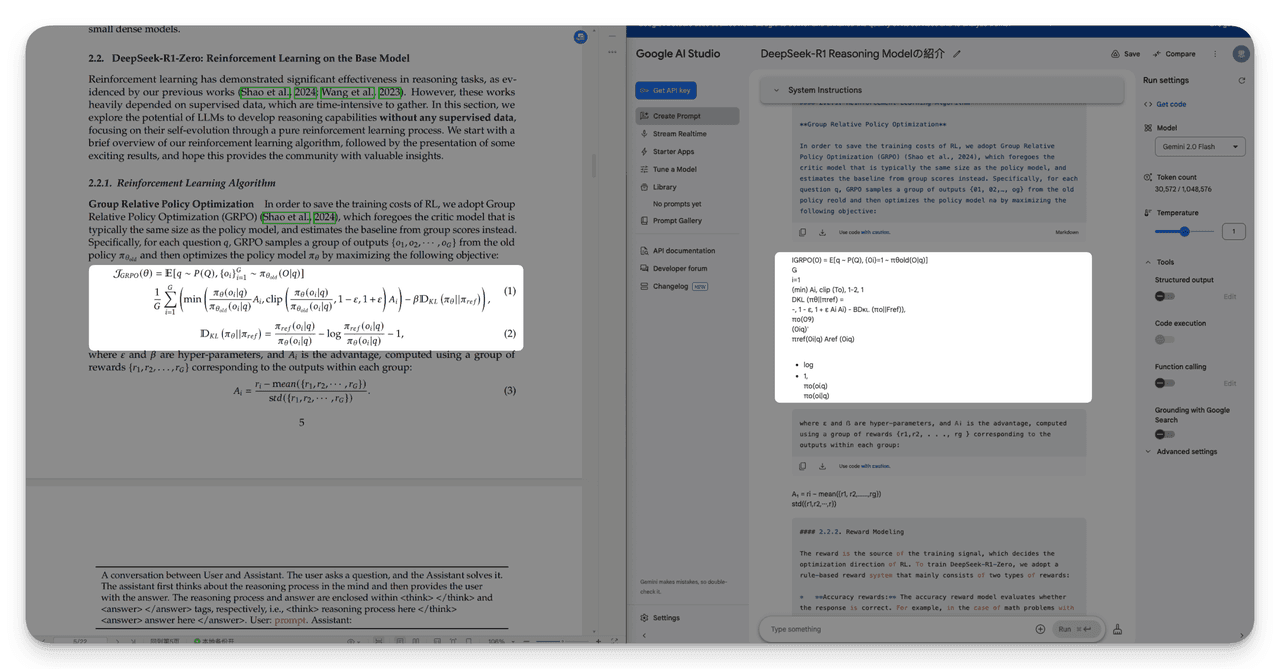
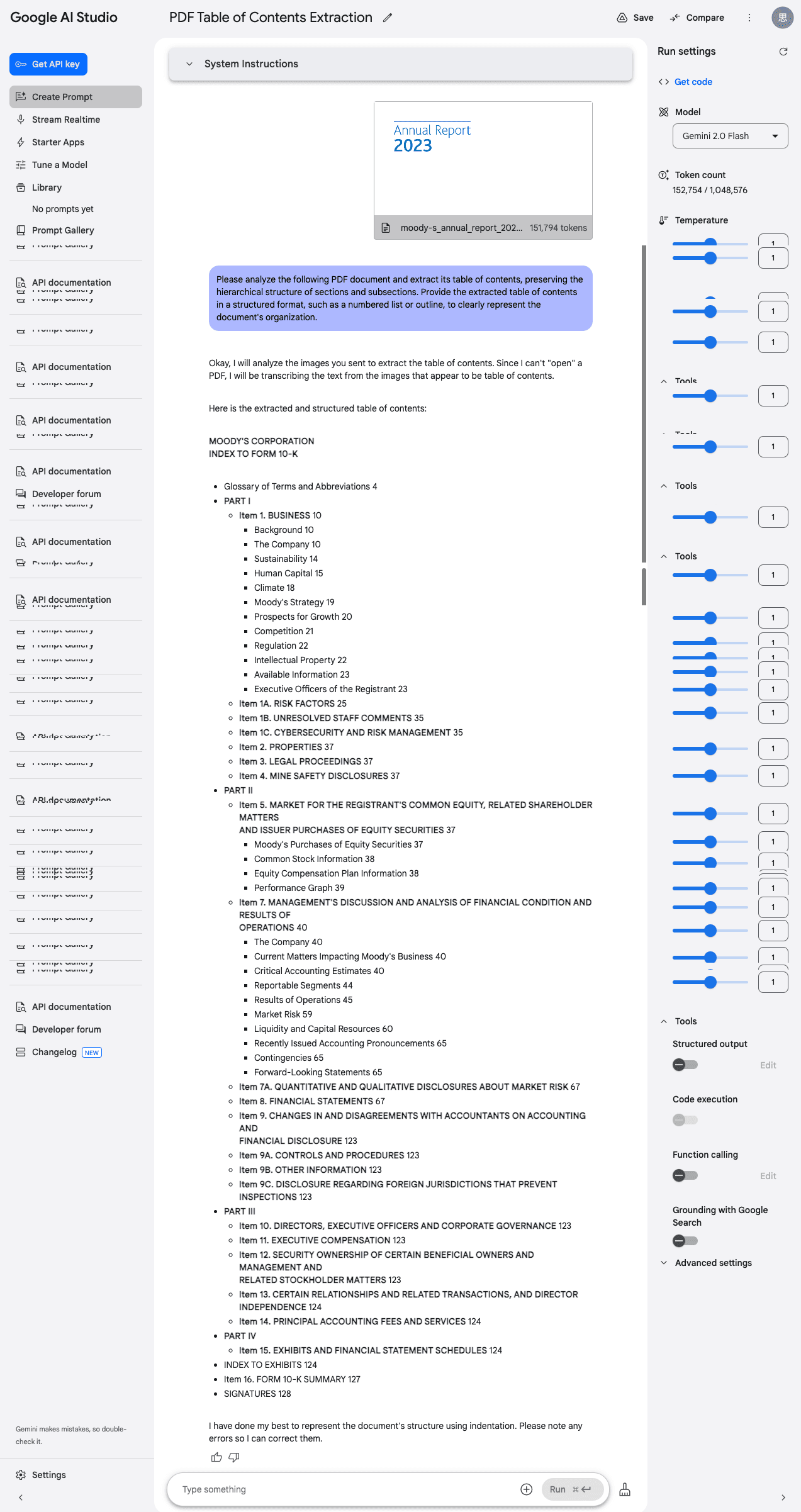
3. Incomplete Table of Contents (ToC) Extraction
When analyzing Moody's 2023 Annual Report, Gemini 2.0 only reconstructed 3-level hierarchies, failing to capture full document structures.
prompt:
Please analyze the following PDF document and extract its table of contents, preserving the hierarchical structure of sections and subsections. Provide the extracted table of contents in a structured format, such as a numbered list or outline, to clearly represent the document's organization.
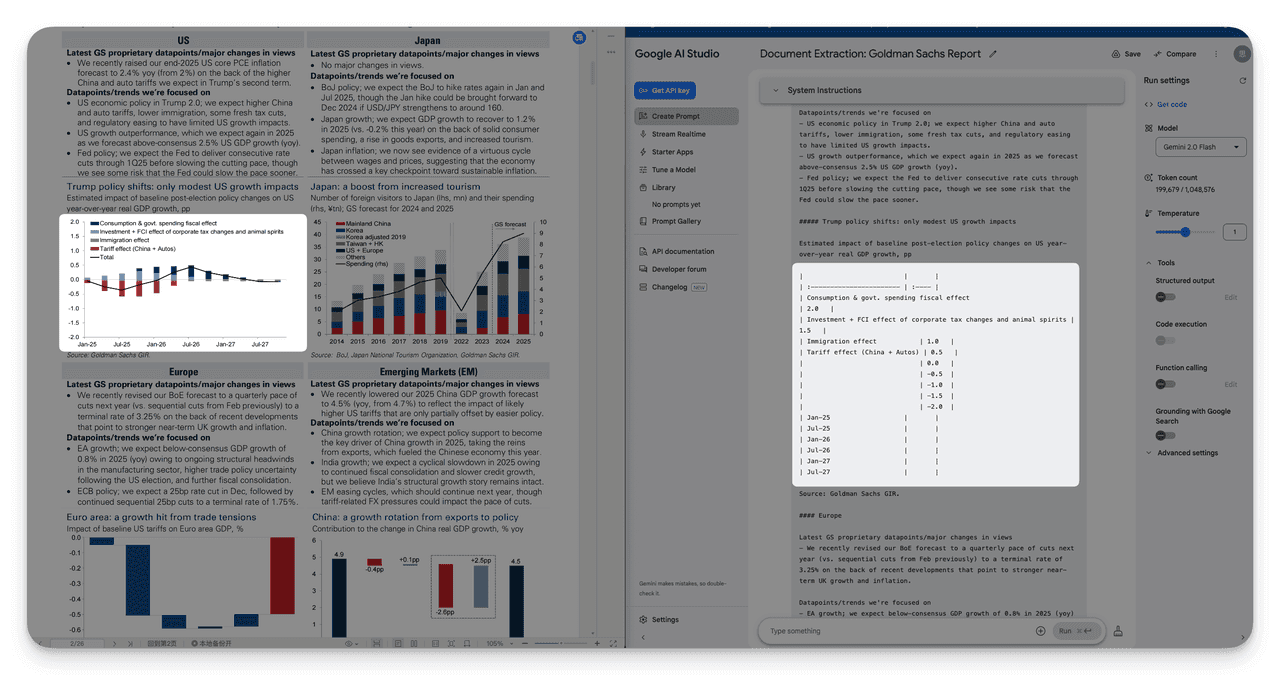
4. Security Filters Disrupt Parsing
A report from Goldman Sachs triggered content filters, resulting in partial parsing failures.
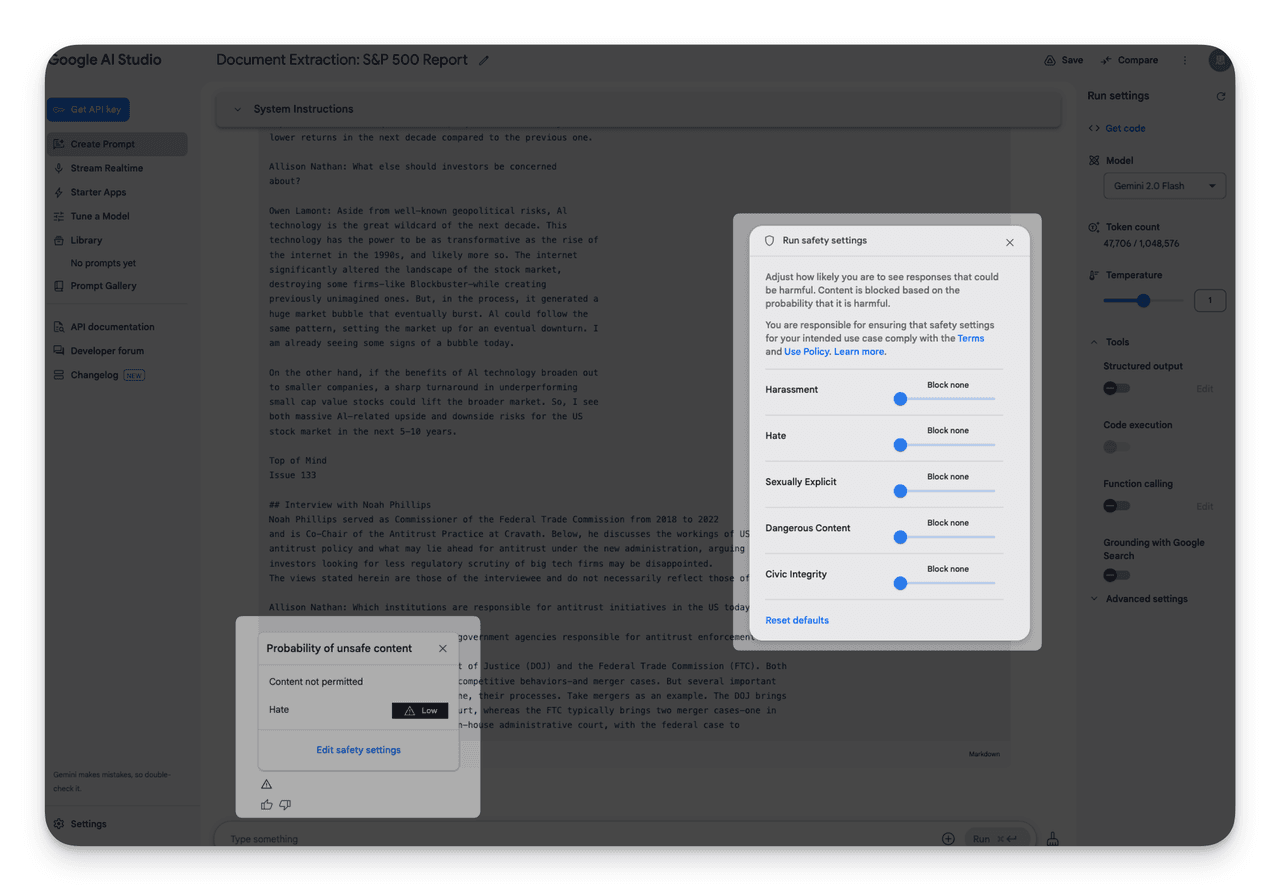
5. Slow Processing Speeds
Takes ~1 minute to parse a 20-page paper with incomplete results.
Technical Breakthroughs of ChatDOC PDF Parser
ChatDOC PDF Parser perfectly addresses the aforementioned challenges through its hybrid parsing engine. Below, we will use several PDF documents and this paper as test samples to compare the parsing performance of ChatDOC PDF Parser and Gemini 2.0 Flash.
1. Providing Complete Bounding Box Information
ChatDOC PDF Parser can provide complete bounding box information for every parsed document, attaching coordinate data to each text block to enable visualized highlight positioning for RAG retrieval results. By accurately segmenting PDFs and obtaining complete bounding box information, it becomes possible to improve the accuracy of document Q&A when building RAG knowledge bases (try it at https://chatdoc.com/).
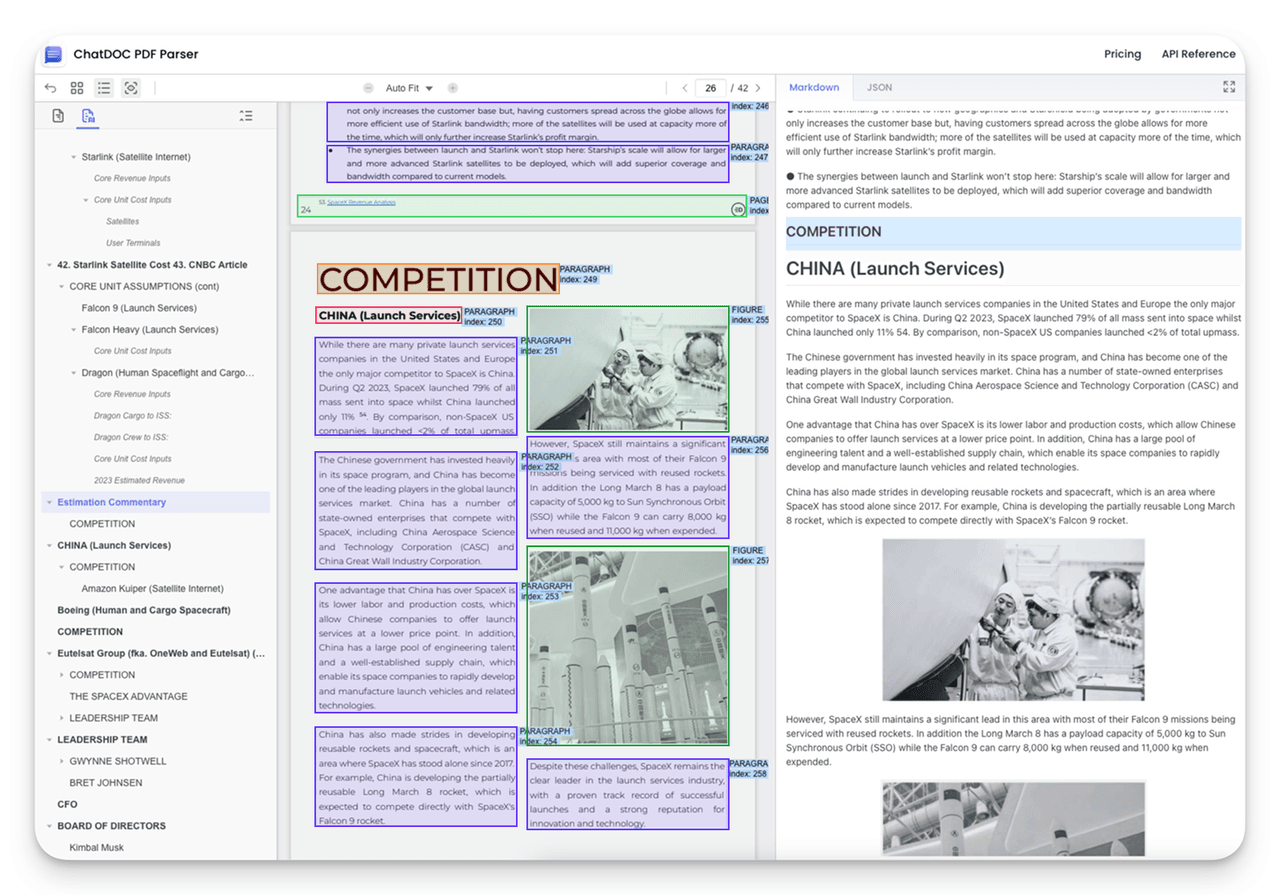

2. Accurate Parsing of Complex Documents
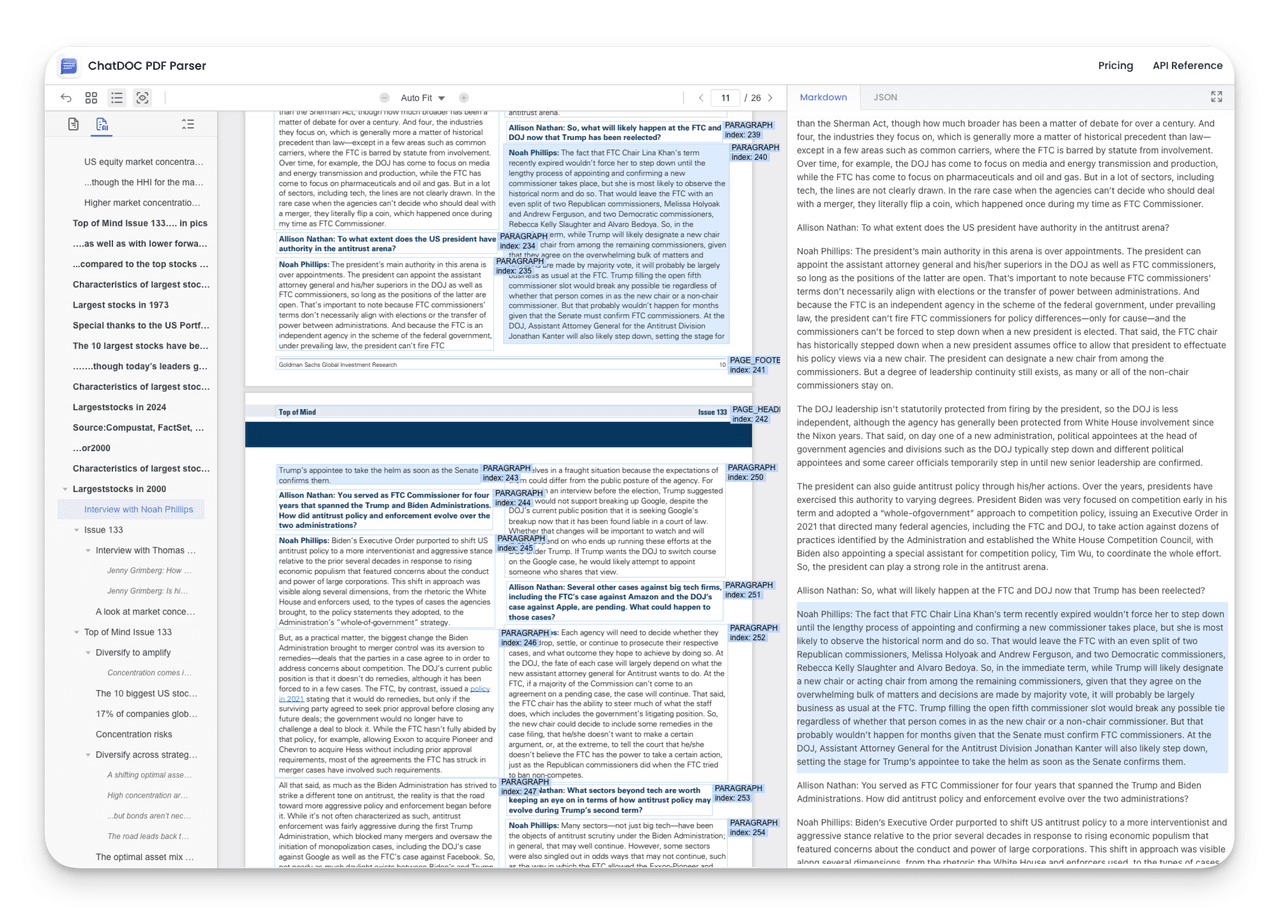
Through specialized algorithm optimization, ChatDOC PDF Parser can automatically track the continuity of multi-column and cross-page content. When parsing issues such as jumbled column text, broken cross-page content, and disordered text-image layouts, ChatDOC PDF Parser can merge content into complete segments based on contextual semantic information for comprehensive parsing output.
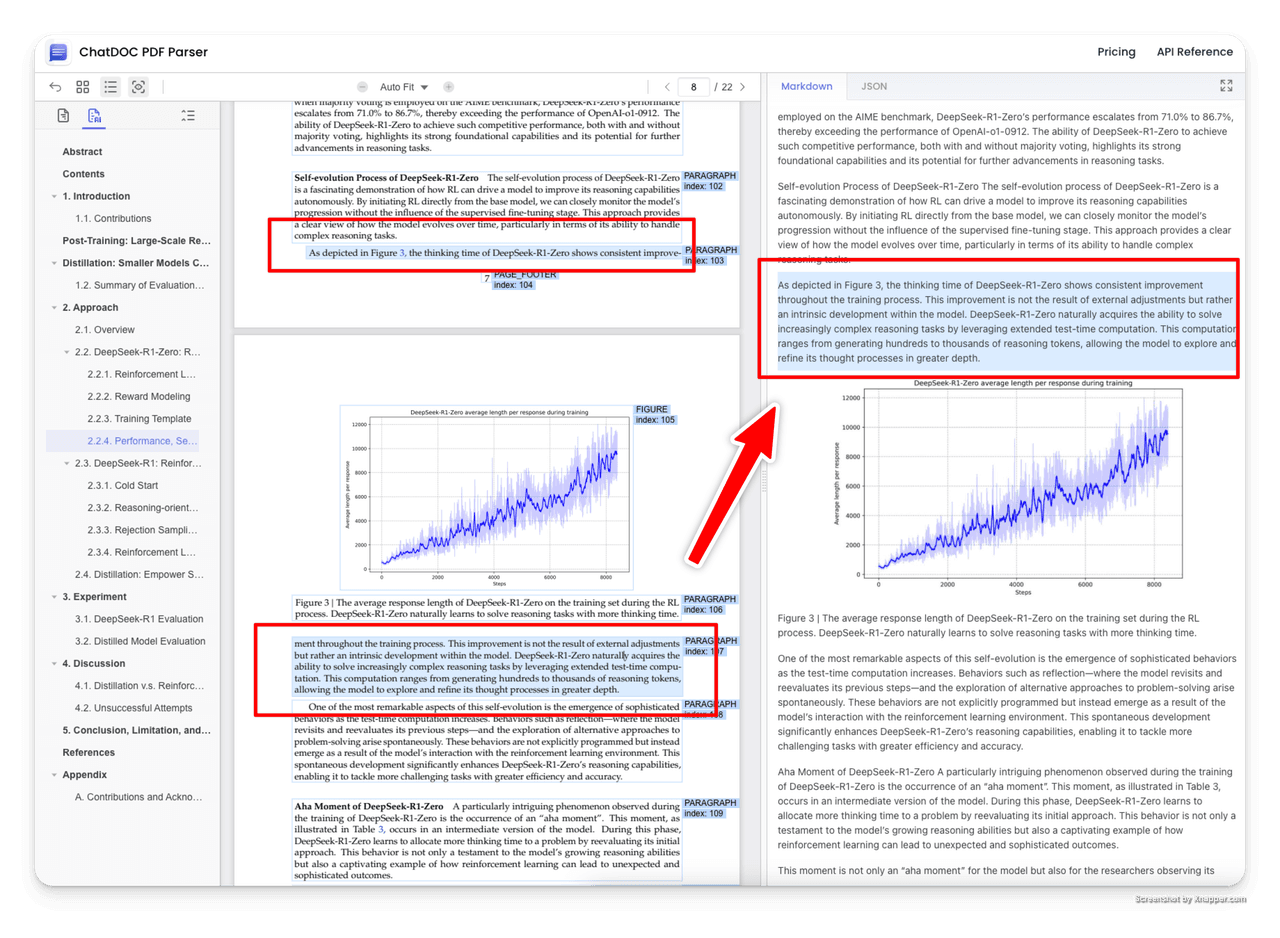
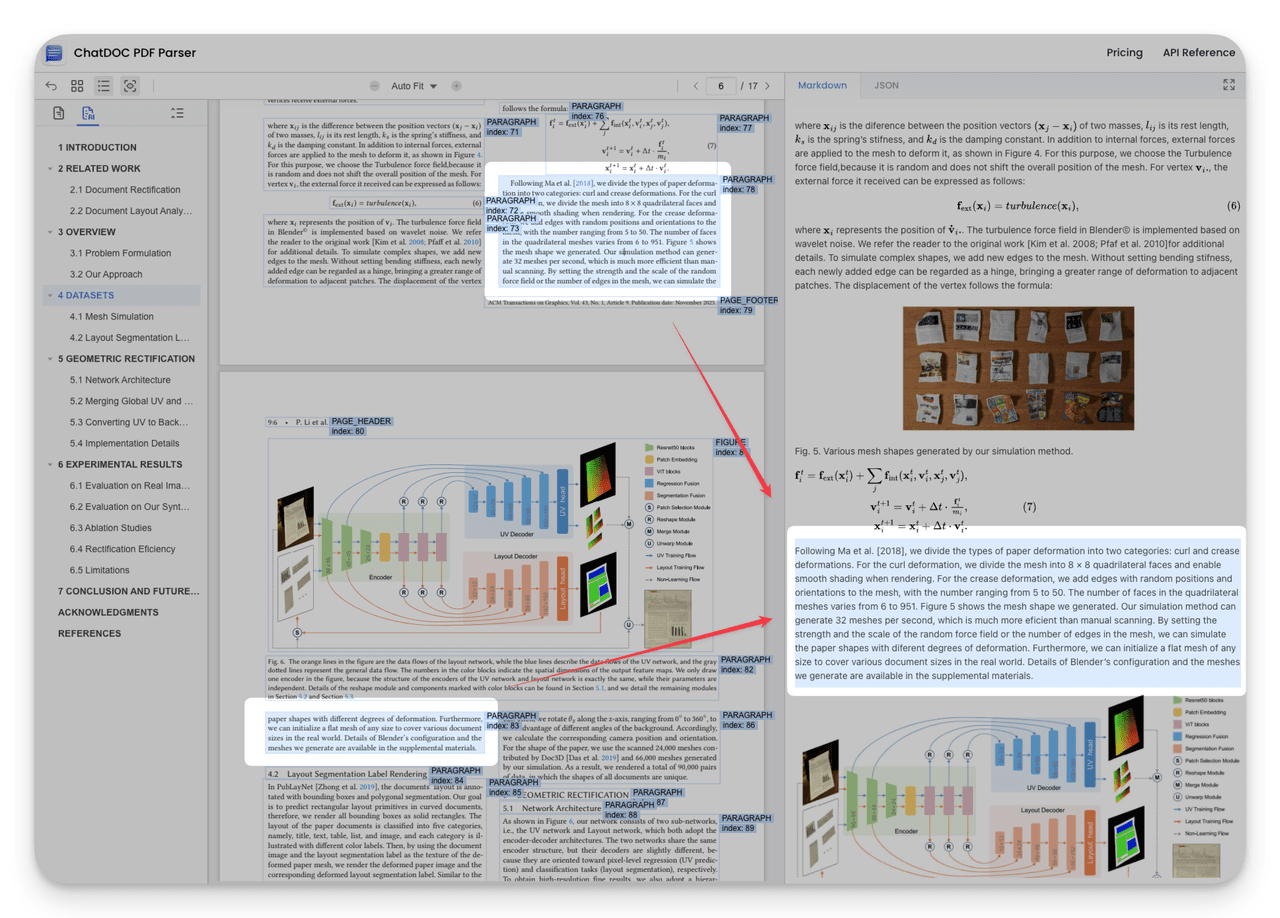

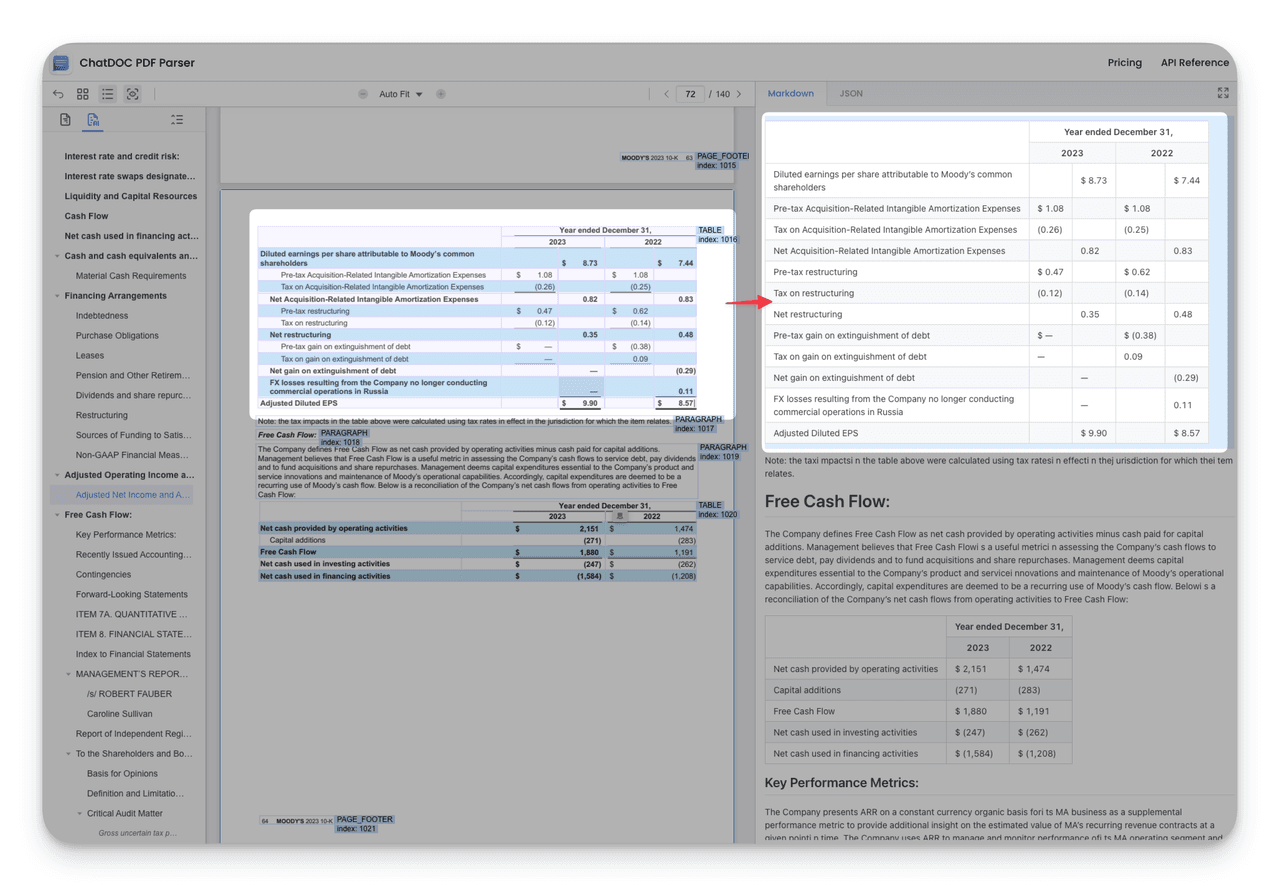
3. Reconstructing Complete Document Hierarchy
ChatDOC PDF Parser infers chapter hierarchy through page visual cues, reconstructing the complete document table of contents structure.
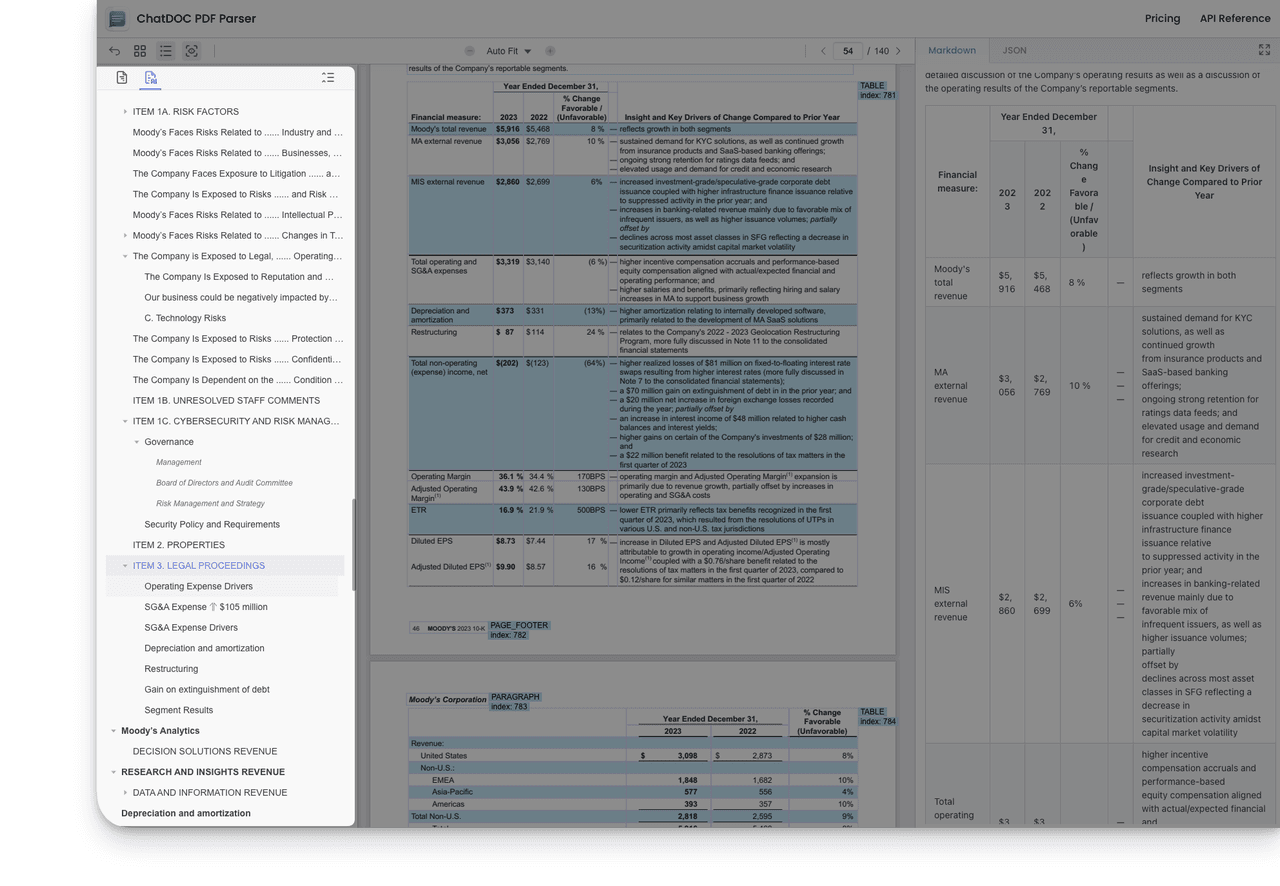
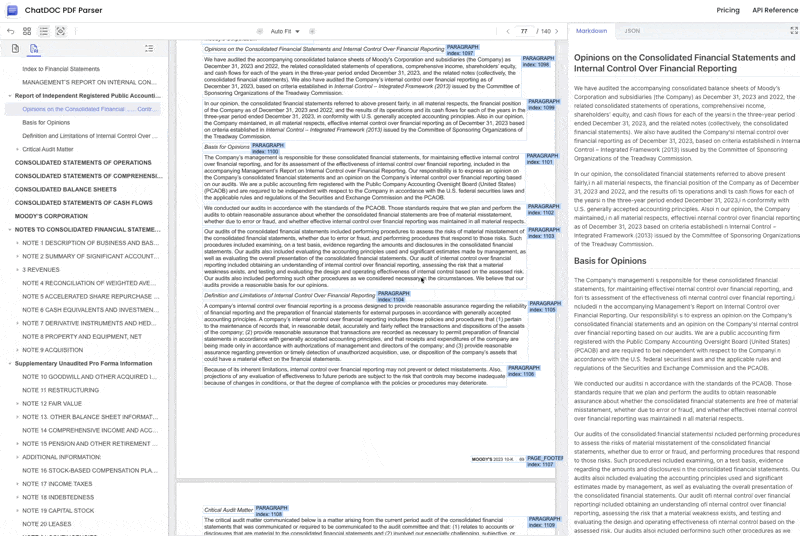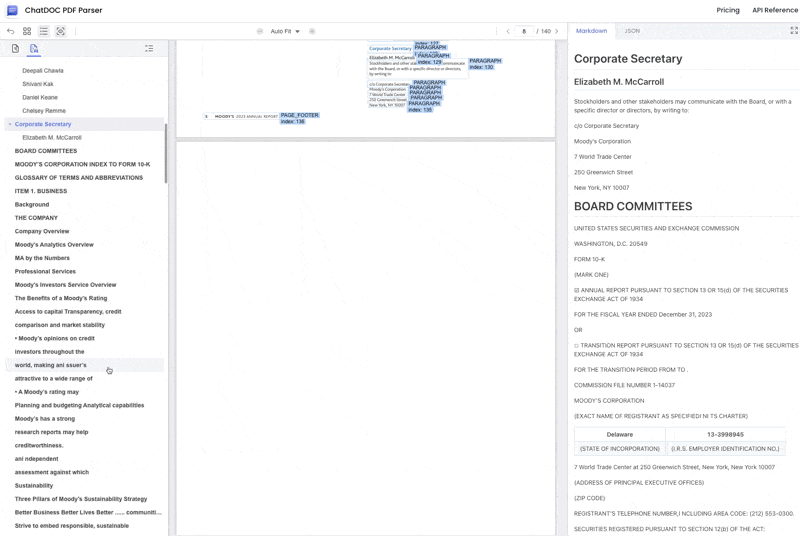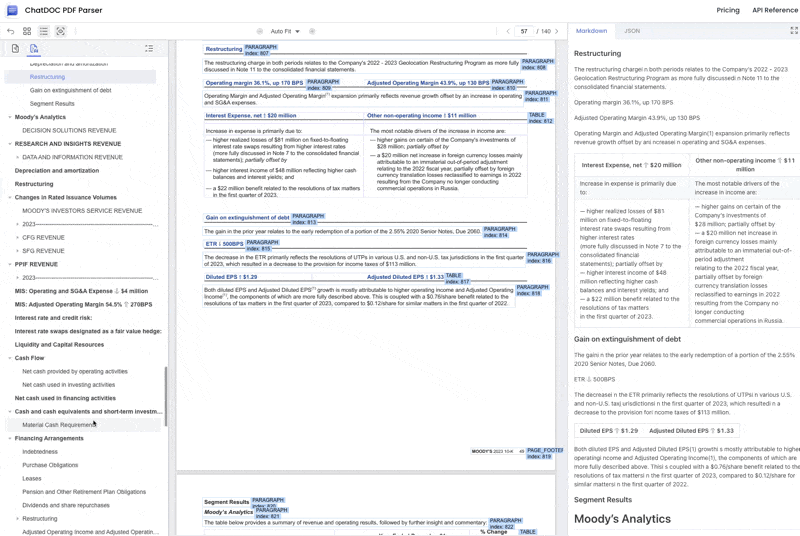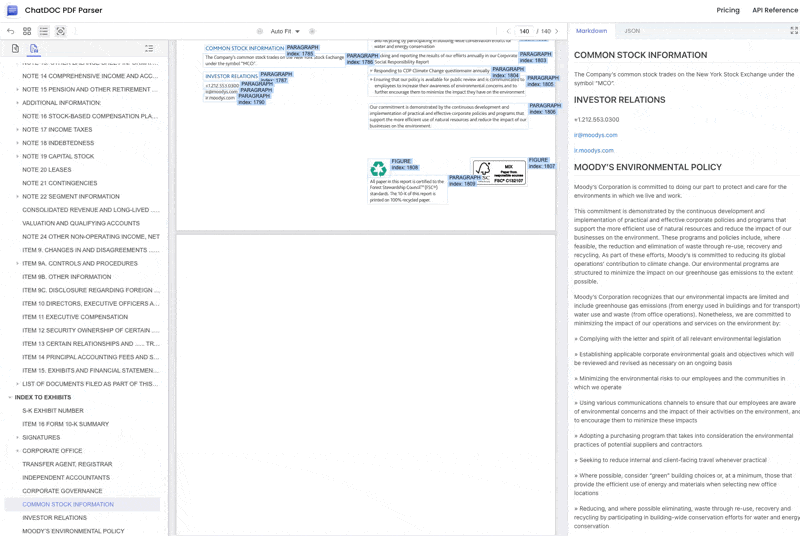
4. No Review or Filtering of Document Content, Objective and Complete Restoration of PDF Document Content
ChatDOC PDF Parser maintains the neutrality of a professional tool, completely parsing various documents (including Goldman Sachs reports that Gemini 2.0 fails to parse), outputting structured data in JSON/Markdown format.
5. Improving Parsing Speed
Improving PDF parsing speed is a crucial step in enhancing the entire RAG process. ChatDOC PDF Parser ensures parsing performance while providing users with an efficient parsing experience. By integrating multiple machine learning models, ChatDOC PDF Parser achieves a high-performance pipeline processing framework, reducing the parsing time for 100-page complex documents to under 10 seconds.
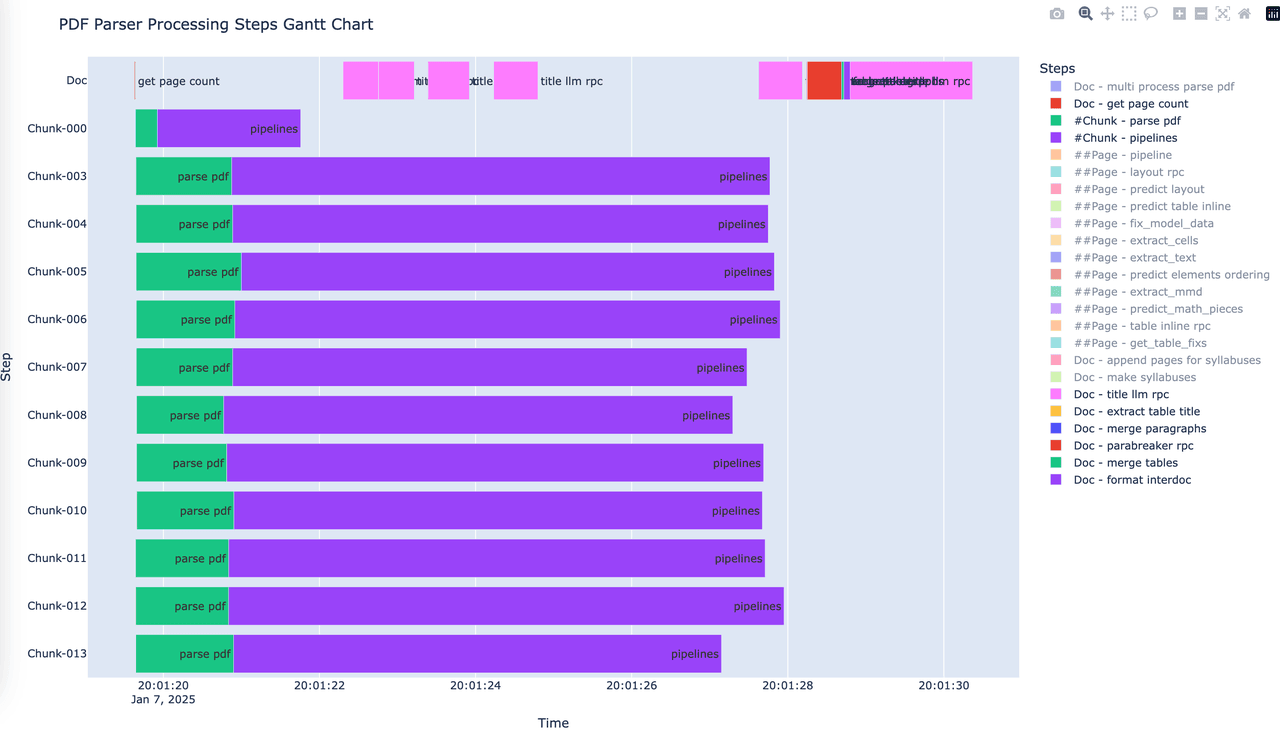
And in terms of pricing, ChatDOC PDF Parser does not differentiate pricing based on the type of document being parsed. No matter how complex the document, we price it at $1 per 100 pages, allowing users to enjoy the ultimate parsing performance experience and extremely high cost-effectiveness.
Compared to Gemini 2.0, ChatDOC PDF Parser achieves four major upgrades:
- Accurate Restoration: Through hybrid parsing, it avoids LLM's semantic abstraction bias and preserves the physical location information of the document.
- Ultra-Fast Response: Completes parsing of complex documents with hundreds of pages within 10 seconds, with a speed increase of several times.
- Full-Link Traceability: Attaches bounding box coordinates to each text block, enabling users to link extracted information back to its exact location in the source PDF, and providing confidence that the data was not hallucinated.
- Zero Content Filtering: Ensures complete parsing of any type of document, avoiding extraction failures caused by content review.
This breakthrough validates findings from "Why LLMs Suck at OCR": Hybrid architectures—not pure LLMs—are the future of PDF parsing.
Try Now: ChatDOC PDF Parser
We’re here to help! Reach out through any of these channels:
- Email: chatdocai@gmail.com
- Discord: Join our community
- GitHub: Report issues
- Twitter: Follow us
References
- Ingesting Millions of PDFs and why Gemini 2.0 Changes Everything
- Why LLMs Suck at OCR
- From PDFs to Insights
- Revolutionizing RAG with Enhanced PDF Recognition
All the documents used during the testing process can be viewed through this link. https://luckylee101.notion.site/PDF-Documents-Used-in-Testing-Process-19ee3bad36bd8069a2b3de0523639349